Institut für Informatik
Lehr- und Forschungseinheit für Datenbanksysteme
Institute for Computer Science
Database and Information Systems
|
|
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme |
University of Munich Institute for Computer Science Database and Information Systems |
Motivation
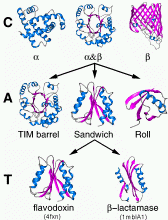
Die Vorhersage der Faltungsklasse eines Proteins basierend auf der Aminosäure-Sequenz
(fold recognition) kann man als Klassifikationsproblem auffassen.
Verschiedene Ansätze hierzu werden auf unterschiedlichen Datensätzen evaluiert.
Dabei differieren die Faltungsklassen-Hierarchien
SCOP
und CATH
oftmals deutlich. Die Spezialisierung auf das Klassensystem von SCOP
zieht daher oft ein schlechteres Abschneiden auf dem Klassen-System von CATH
nach sich (und umgekehrt).
|
|
|
Aufgabenstellung |
||
|
|
Basierend auf einem großen Protein-Datensatz sollen die Unterschiede in den Klassensystemen
von SCOP und CATH genauer analysiert werden. In einem zweiten Schritt soll ein
(aktualisierbarer) Konsens-Datensatz für gegebene Versionen von SCOP und CATH
bereitgestellt werden.
|
|
| Johannes Aßfalg |
| ||||||||||
| Dr. Arthur Zimek |
|