Institut für Informatik
Lehr- und Forschungseinheit für Datenbanksysteme
Institute for Computer Science
Database and Information Systems
|
|
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme |
University of Munich Institute for Computer Science Database and Information Systems |
Motivation
Traditionelle Data Mining Methoden sind normalerweise ineffizient und
ineffektiv für hochdimensionale Daten. Der Grund hierfür ist der
sogenannte Curse of Dimensionality (Fluch der
Dimensionalität). Dies ist ein Sammelbegriff für eine Reihe
von Phänomenen, die für Punktmengen in hochdimensionalen
Featureräumen gelten. Beispielsweise nähern sich in
hochdimensionalen Räumen die Distanzen des nächsten Nachbarn und
des entferntesten Nachbarn eines beliebigen Punktes an. Als Folge
hieraus können Daten nicht mehr anhand ihrer paarweisen
Distanzen untersucht werden.
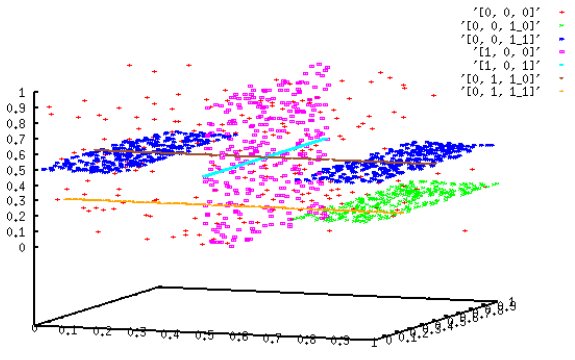
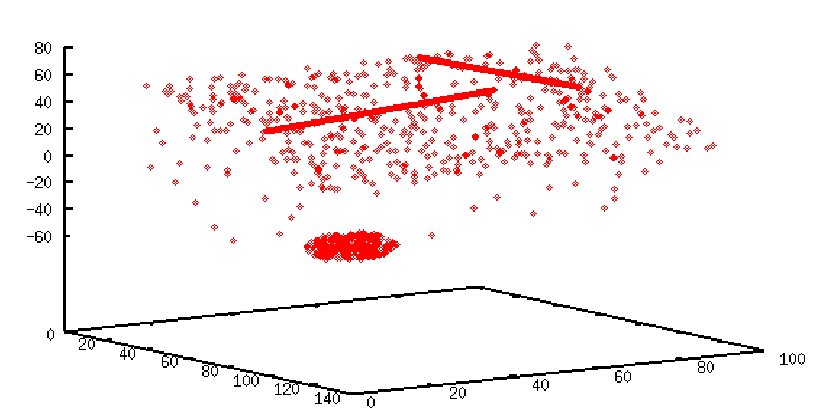
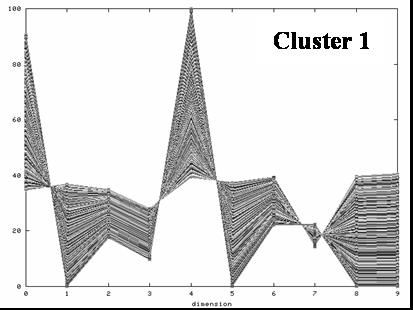
Speziell Clustering und Outlier Detection Methoden leiden unter dem Curse of Dimensionality. Die Datenobjekte sind im gesamten Datenraum mehr oder weniger gleich verteilt, d.h. es existieren keine Cluster oder Outlier. Oft ist es allerdings so, dass Cluster und/oder Outlier in Teilrämen des Datenraumes existieren. Im Rahmen dieses Projektes geht es darum, Cluster und Outlier in Teilräumen des gesamten Datenraumes zu finden. Dafür gibt es zwei Vorgehensweisen:
|
|
|
Aufgabenstellung
Im Rahmen von zukünftigen Diplom- und Projektarbeiten sollen neue
Techniken zum Data Mining in hochdimensionalen Daten entwickelt,
implementiert und getestet werden. Dabei wird sich die Arbeit auf
Verfahren zum Clustering und Outlier Detection konzentrieren. Im
Bereich des Clusterings sollen Methoden zur Ableitung von
Clusterbeschreibungen und Clustermodellen erarbeitet werden. Zudem
sollen Möglichkeiten zur übersichtlichen Visualisierung der Data
Mining Resultate untersucht werden.
|
| Dr. Peer Kröger | Raum : E 1.08 Telefon : 089 / 2180 9327 |
| Dr. Arthur Zimek | Raum : E 1.06 Telefon : 089 / 2180 9325 |