| |
|
|
 |
Clustering High Dimensional Data |
 |
Clustering real-world data sets is often hampered by the so-called curse of dimensionality: many real-world data sets consist of a very high dimensional feature space. In general, most of the common algorithms fail to generate meaningful results because of the inherent sparsity of the data space. Usually, clusters cannot be found in the original feature space because several features may be irrelevant for clustering due to correlation and/or redundancy. However, clusters are usually embedded in lower dimensional subspaces. In addition, different sets of features may be relevant for different sets of objects. Thus, objects can often be clustered differently in varying subspaces of the original feature space.
1. Subspace Clustering and Subspace Ranking
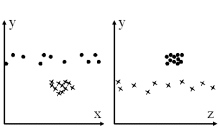
Subspace clustering aims at computing all clusters in all subspaces of the feature space. The information of objects clustered differently in varying subspaces is conserved. Objects may be assigned to several clusters (in different subspaces).
Subspace ranking aims at identifying all subspaces of a (high dimensional) feature space that contain interesting clustering structures. The subspaces should be ranked according to this interestingness.
SUBCLU (density-based SUBspace CLUstering)
SUBCLU is a subspace clustering algorithm that relies on the density-based clustering notion of DBSCAN. It efficiently computes all clusters DBSCAN would have found if applied to the set of all possible subspaces of the feature space. SUBCLU uses an Apriori-like subspace generation procedure which is based on the monotonicity property of density-connected sets and which ensures that only those subspaces are examined that contain clusters.RIS (Ranking Interesting Subspaces)
RIS is a subspace ranking algorithm that uses a quality criterion to rate the interestingness of subspaces. This criterion is based on the monotonicity of core points which are the central concept of the density-based clustering notion of DBSCAN. An Apriori-like subspace generation method (similar to SUBCLU) is used to compute all relevant subspaces and rank them by interestingness. The clusters can be computed in the generated subspaces using any clustering method of choice.SURFING (SUbspaces Relevant For clusterING)
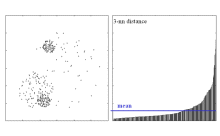
SURFING is a subspace ranking algorithm that does not rely on a global density threshold. It computes the interstingness of a subspace based on the distribution of the k-nearest neighbors of all data points in the corresponding projection. An efficient, bottom-up subspace expansion heuristics ensures that less interesting subspaces are not generated for examination.
2. Projected Clustering and Correlation Clustering
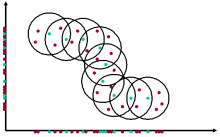
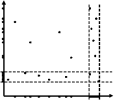
Projected clustering aims at partitioning the data into a set of clusters and a noise set while allowing the clusters to exist in different subspaces. Thus, for each cluster, a different set of features is relevant, whith the remaining features being irrelevant. The points of each cluster are densely packed in the subspace spanned by the corresponding relevant features but are sparsely distributed in the subspace spanned by the other dimensions.
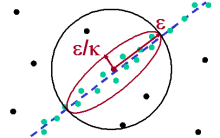
Correlation clustering aims at partitioning the data objects into distinct sets of points that exhibit a dense, arbitrarily linear correlation, so called correlation sets. Points that do not belong to any correlation set are classified as noise.
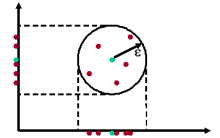
PreDeCon (subspace PREference weighted DEnsity CONnnected clustering)
PreDeCon extends the 'full-dimensional' clustering algorithm DBSCAN with the concept of subspace preference weights. For each point, the local neighborhood is examined to determine a subspace tendency, i.e. an axis parallel projection onto which the point is located in a dense area. If the point is noise, this subspace is the entire feature space. Neighboring points having a similar subspace preference weight are grouped into clusters using the density-connected clustering notion.4C (Computing Correlation Connected Clusters)
4C computes so-called correlation connected clusters, i.e.sets of neighboring points that exhibit an arbitrary linear correlation in a subset of the attributes. For that purpose, 4C examines the correlation in the neighborhood of each point and groups points with similar local correlation into clusters.
Gene Expression Analysis
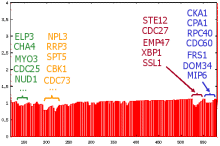
Micro array chips enable measuring the expression level (i.e. the intensity of the expression) of thousands of genes simultaneously under different conditions or in different tissues. Cluster analysis aims at identifying homogeneous groups of genes with a similar expression behavior in subsets of samples indicating functional relationships. Knowing about functional relationships among genes is important for understanding gene regulation.E-Commerce
In recommendation systems and target marketing it is important to find homogeneous groups of users with similar ratings in subsets of the attributes. In addition, it is interesting to find groups of users with correlated affinities. This knowledge can help companies to predict customer behavior and thus develop future marketing plans.Metabolic Screening
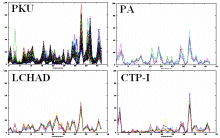
Metabolic Screening Data usually contain the concentrations of certain metabolites in the blood of thousands of patients. In such data sets it is important to find homogeneous groups of patients with correlated metabolite concentrations indicating a common metabolic disease. This is an important step towards understanding metabolic/genetic disorders and designing individual drugs.
Bei Problemen oder Vorschlägen wenden Sie sich bitte an:
wwwmaster@dbs.informatik.uni-muenchen.de
Last Modified:
2004-Sep-22