|
|
|
|
 |
Density-Based Cluster- and Outlier Analysis |
Cluster analysis is a primary method for database mining. It is either used as a stand-alone tool to get insight into the distribution of a data set, e.g. to focus further analysis and data processing, or as a preprocessing step for other algorithms operating on the detected clusters. Density-based approaches apply a local cluster criterion. Clusters are regarded as regions in the data space in which the objects are dense, and which are separated by regions of low object density (noise). These regions may have an arbitrary shape and the points inside a region may be arbitrarily distributed.
For other KDD applications, finding the outliers, i.e. the rare events, is more interesting and useful than finding the common cases, e.g. detecting criminal activities in E-commerce.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
The algorithm DBSCAN, based on the formal notion of density-reachability for k-dimensional points, is designed to discover clusters of arbitrary shape. The runtime of the algorithm is of the order O(n log n) if region queries are efficiently supported by spatial index structures, i.e. at least in moderately dimensional spaces.GDBSCAN (Generalized Density-Based Spatial Clustering of Applications with Noise)
GDBSCAN generalizes the notion of point densitiy and therefore it can be applied to objects of arbitrary data type, e.g. 2-dimensional polygons.
The code for GDBSCAN (including the specialization to DBSCAN) is available by e-mail from Dr. Jörg Sander.OPTICS (Ordering Points To Identify the Clustering Structure)
While DBSCAN computes a single level clustering, i.e. clusters of s single, user defined density, the algorithm OPTICS represents the intrinsic, hirarchical structure of the data by a (one-dimensional) ordering of the points. The resulting graph (called reachability plot) visualizes clusters of different densities as well as hierachical clusters.
Click here for our Online-Demo. The code for OPTICS is available by e-mail from Dr. Jörg Sander or Markus Breunig.LOF (Local Outlier Factors)
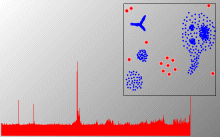
Based on the same theoretical foundation as OPTICS, LOF computes the local outliers of a dataset, i.e. objects that are outliers relative to their surrounding space, by assigning an outlier factor to each object. This outlier factor can be used to rank the objects regarding their outlier-ness. The outlier factors can be computed very efficiently if OPTICS is used to analyze the clustering structure.
Landuse Detection
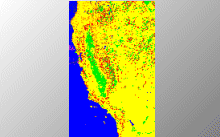
DBSCAN has been applied to a 5-dimensional feature space created from several satellite images covering the area of California (5 different spectral channels: 1 visible, 2 reflected infrared, and 2 emitted (thermal) infrared). The images are taken from the raster data of the SEQUOIA 2000 Storage Benchmark. This kind of clustering application is one of the basic methods for automatic landuse detection from remote sensing data.Potential Protein Docking Sites
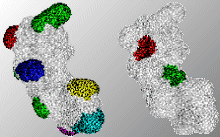
The points on a protein surface (3d points) can be clustered with GDBSCAN to extract connected regions having a high degree of convexity or concavity. To find such regions is a subtask for the problem of protein-protein docking.Influence Regions in GIS
GDBSCAN can be used to cluster 2d polygons from a geographic database, taking also into account the non-spatial attributes of the polygons. The found clusters, i.e. the so-called influence regions, are the input for a spatial trend detection algorithm.Web-User Profiles
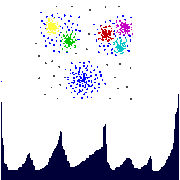
The goal of clustering Web-log sessions is to discover groups of access patterns which similar with respect to a suitable similarity measure. These access patterns characterize different user groups. This kind of information may, for example, be used to develop marketing strategies.Color Histograms
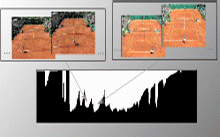
The clustering of an image database containing 64-dimensional color histograms of 112,000 images from TV snapshots yield groups of similar images (with respect to color frequencies). To know these clusters is useful when searching for suitable images that must be similar to a given picture.
Bei Problemen oder Vorschlägen wenden Sie sich bitte an:
wwwmaster@dbs.informatik.uni-muenchen.de
Last Modified: