Suitability of data sets for outlier detection
Difficulty vs. diversity
Diversity versus Difficulty of datasets with 3%-5% outliers (without duplicates, normalized). For each dataset with different downsampled variants, the 95% confidence ellipse is shown as well as the individual points for each variant. The means of the ellipses, which do not correspond to actual data instances, are indicated by an 'X' showing the name of the corresponding base dataset beside it.

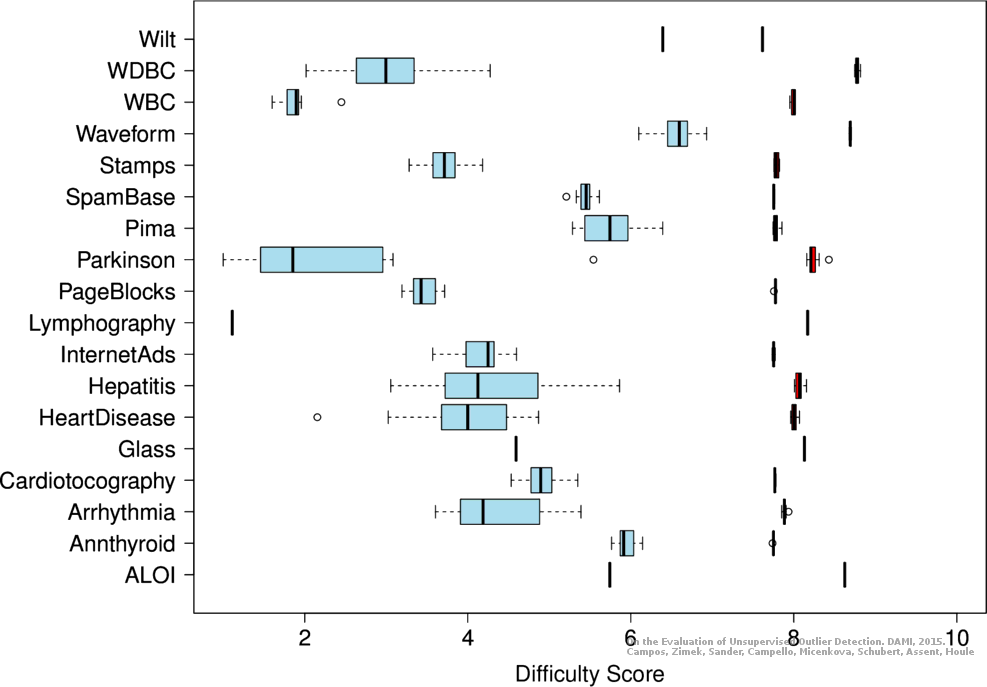
Distribution of difficulty scores
Distribution of observed difficulty scores for each dataset, and in the same line to the right, for each dataset the distribution of difficulty scores obtained after randomizing the ground truth labels.